

A l’occasion de la journée internationale des droits des femmes le 8 mars 2020, l’ARPP vient de procéder à l’analyse automatique de la représentation des genres dans la publicité TV et VOD diffusée en 2019 (21 795 films), grâce à de nouveaux modèles de Machine Learning désormais en production, détectant les visages, le genre, la voix et l’âge.
Une démarche qui demeure inédite au monde et que nous vous dévoilons dans ce billet, avec l’aide d’Antoine, Pierre-Henri et Yohann, Data scientists et Software architect chez Ipanema Consulting / Digigladd.
L’an dernier, nous annoncions avoir procédé à la classification des genres dans la publicité audiovisuelle (Reconnaissance basée sur le visage uniquement), grâce à l’intelligence artificielle, pour l’intégralité de la production publicitaire TV et VOD diffusée en 2018.
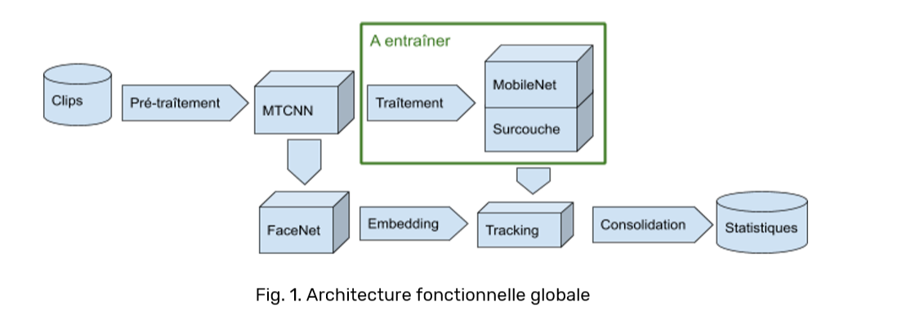
Cette année, l’ARPP transforme le POC en un service désormais en production en étendant le périmètre de son dispositif d’apprentissage supervisé à la détection de la voix et de l’âge, en plus du visage.
Etat de l’art et méthodologie
Les références des différents jeux de données utilisés pour entraîner les divers algorithmes et réseaux de neurones utilisés furent les suivants :
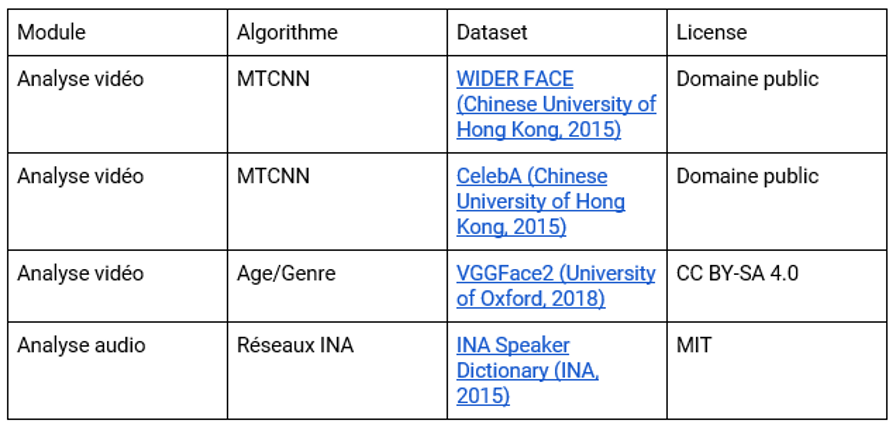
Ainsi 21 795 films (soit près de 131 heures) ont été analysés par ces modèles d’apprentissage supervisé, une tâche relevant de l’impossible pour un être humain.
La détection des visages n’est plus une difficulté en 2020…
Pour les visages, il a fallu recourir à l’apprentissage profond au moyen de réseaux convolutionnels dits « en cascade » (MTCNN).
Deux auteurs scientifiques, Zhang et al., ont publié une méthode dédiée à ce sujet, consistant à détecter les visages en trois phases :
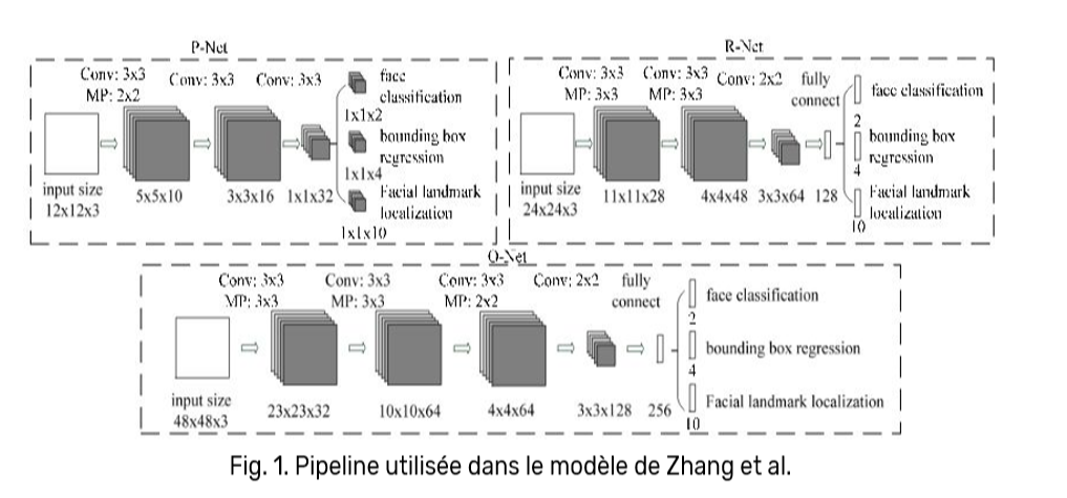
Les tests réalisés sur ce modèle, de plus en plus répandu, furent très concluants grâce aux trois phases représentées dans la figure ci-dessus :
- La première phase consiste à produire un grand nombre de candidats à travers un réseau de neurones peu profond.
- Les deux phases suivantes utilisent des réseaux plus puissants et profonds pour affiner successivement les résultats.
La détection de l’âge et du genre
Une fois les visages détectés avec le réseau MTCNN, l’étape suivante à consiste à les classifier selon leur âge et leur genre.
Les implémentations récentes ont fait preuve, pour le genre d’une précision allant de 70% à 95%[2] et pour l’âge de 50% à 80%[3] (tranche de 5 années).
Concernant l’âge, il était initialement prévu d’utiliser une base ResNet-50/UTKFace (voir figue ci-dessous) :
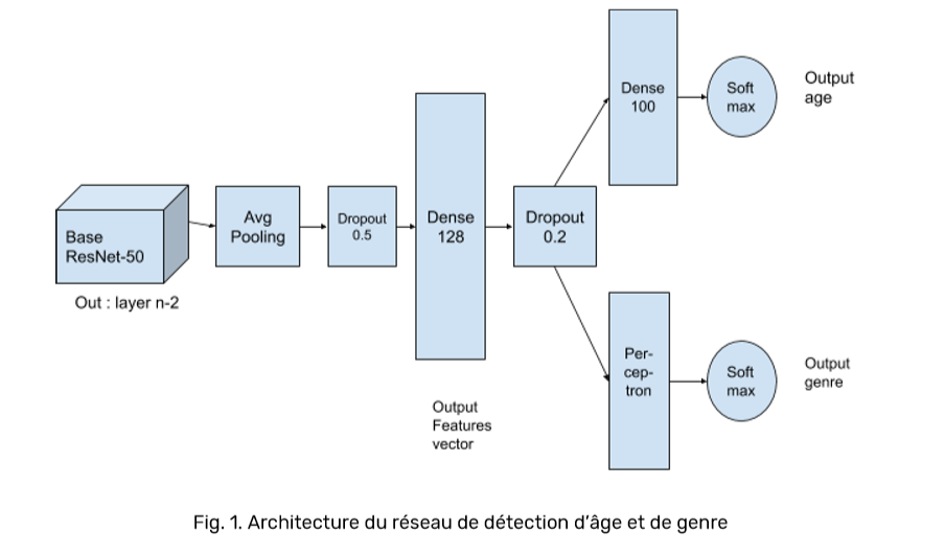
Cependant, il fut constaté qu’une autre base (MobileNet/UTKFace) arrivait à des performances très similaires pour un coût en ressources bien moindre (voir figure ci-dessous).
Ce réseau s’est révélé assez rapide à entraîner. Un taux de précision de 92,2% sur le genre, et 86,5% d’efficacité sur l’âge (pour des tranches de 5 ans) furent atteints sur le jeu de données utilisé. Concernant le genre, le résultat est donc supérieur à celui de l’an dernier (87%).

Sur la figure ci-dessus, nous constatons un résultat concluant (en effet, les indicateurs d’âge, de genre, et d’unicité d’identité sont corrects), malgré la complexité qu’elle présente (tranches d’âge très différentes, personnes qui se ressemblent, visages de profil, potentiels faux positifs avec les animaux…).
Comment identifier un individu unique ? Ou la problématique du tracking….
Un des challenges de cette analyse était celui de l’identification d’un individu unique (méthode dite du tracking).
En effet, à un instant t+1, il faut déterminer si les visages détectés appartiennent à la même personne qu’à l’instant t0.
Pour réaliser le tracking, il a d’abord été décidé de récupérer les représentations vectorielles de tous les visages analysés (features vectors) et d’effectuer un clustering sur leurs distances euclidiennes [5] pour déterminer différentes identités.
En l’état, cette méthode s’est révélée peu efficace : en effet, le vecteur possède 128 dimensions, et pour de petits visages possédant une expression similaire l’algorithme n’arrive pas à les séparer en plusieurs identités, comme en témoigne l’image ci-dessous :
![]()
Les implémentations de tracking actuelles sont extrêmement performantes uniquement si elles sont déjà entraînées de manière supervisée sur les personnes qu’elles sont censées reconnaître (par exemple : la reconnaissance d’une célébrité).
Il a finalement été décidé :
- de récupérer les feature vectors dans une couche dense de 1024 dimensions directement dans le réseau en amont (ResNet-50).
- Et de coupler ces données à un tracking de position à partir des points clés détectés dans chaque visage tout au long de chaque plan de caméra.
Cette approche a permis d’obtenir des résultats bien meilleurs comme en témoigne la capture ci-dessous :
![]()
L’Analyse des voix : Merci l’Institut National de l’Audiovisuel !
Concernant l’analyse des voix, nous nous sommes appuyés sur le réseau convolutionnel de segmentation audio construit par l’INA en 2018.
Les modèles ont été entrainés sur le Speaker Dictionnary de l’INA (speechtrax.ina.fr).
Il s’agit de la plus grande base de données d’orateurs qui en recense 2274 différents, pour 32 000 extraits audio en français et 120 heures de programmes radio et TV.
Selon la littérature académique, le taux de précision atteint est de 94%.
Les clips audio n’étant pas exclusivement composés de voix, mais aussi de bruit, de musique et de silence, l’INA propose un premier réseau convolutionnel permettant de classifier un segment de 680 millisecondes comme étant de la voix ou non[6].
Les segments classifiés comme contenant de la voix sont ensuite passés à un second réseau convolutionnel profond, d’architecture similaire pour détecter le genre de l’orateur[7].
Quelques premiers indicateurs…
Présence humaine pour l’année 2019 : 56 174 individus identifiés.
L’âge moyen entre hommes (31 ans) et femmes (29 ans) est équitable.
L’étude permet de révéler cette année encore que sur la durée totale des films analysés, une proportion de 42,7 % du temps présente au moins un être humain, dont le temps de présence féminine détectée sur la durée totale visualisée d’individus de 50,8 %.
L’étude nous apprend par ailleurs que 6 adultes sur 10 accompagnant au moins un enfant montré dans une publicité TV/SMAd sont des hommes.
Un outil aux mains des adhérents de l’ARPP !
Les modèles détaillés dans ce billet sont à présent déployés en production sur une infrastructure cloud et sont dorénavant activables sur toutes les campagnes TV et VOD soumises à l’avis avant diffusion de l’ARPP.
Ainsi, l’ARPP et les représentants de la profession qu’elle regroupe, se voient donc dotés d’un outil qui permettra aux marques et leurs agences d’appréhender objectivement l’équilibre de la représentation des genres dans leurs campagnes et entreprendre toute action qu’elles jugeraient pertinentes.
Vous êtes une marque ou une agence désireuse de connaître quel est l’équilibre de la représentation des genres dans vos campagnes ? Contactez l’ARPP !
Pour en savoir plus sur la méthode suivie : https://digigladd.com/analyse-du-paysage-audiovisuel-publicitaire-avec-des-reseaux-de-neurones-2/




[1]Analyse vidéo (MTCNN) :http://shuoyang1213.me/WIDERFACE/ et http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html / Analyse âge/genre : http://www.robots.ox.ac.uk/~vgg/data/vgg_face2/ / Analyse audio (réseaux INA) : http://recherche.ina.fr/eng/Details-projets/Speech-Trax
[2] A. Bartle, J.Zheng et al., Gender Classification with Deep Learning, 2015.
[3] [10] R. Rothe, R. Timofte, L.V. Gool, DEX: Deep EXpectation of apparent age from a single image, 2015.
Zhang et al., Fine-Grained Age Estimation in the Wild with Attention LSTM Networks, 2018.
Agustsson, R. Timofte et al., Apparent and real age estimation in still images with deep residual regressors on APPA-REAL database, 2017.
[4] R. Rothe, R. Timofte, L.V. Gool, DEX: Deep EXpectation of apparent age from a single image, 2015.
Eran Eidinger, Roee Enbar et al., Age and Gender Estimation of Unfiltered Faces, 2014.
Andrey V. Savchenko, Efficient Facial Representations for Age, Gender and Identity Recognition in Organizing PhotoAlbums using Multi-output CNN, 2017.
[5] C. Biemann, Chinese Whispers – an Efficient Graph Clustering Algorithm and its Application to Natural Language Processing Problems.
[6] D. Doukhan, E. Lechapt, M. Evrard, J. Carrive, INA’s MIREX 2018 music and speech detection system.
[7] D. Doukhan, J. Carrive, F. Vallet, A. Larcher, S. Meignier, An Open-Source Speaker Gender Detection Framework for Monitoring Gender Equality, 2018.
« Très bel article! Aymeric inpong »